bpfman's Shift Towards a Daemonless Design and Using Sled: a High Performance Embedded Database
As part of issue #860 the community has steadily been converting all of the internal state management to go through a sled database instance which is part of the larger effort to make bpfman completely damonless.
This article will go over the reasons behind the change and dive into some of the details of the actual implementation.
Why?
State management in bpfman has always been a headache, not because there's a huge amount of disparate data but there's multiple representations of the same data. Additionally the delicate filesystem interactions and layout previously used to ensure persistence across restarts often led to issues.
Understanding the existing flow of data in bpfman can help make this a bit clearer:
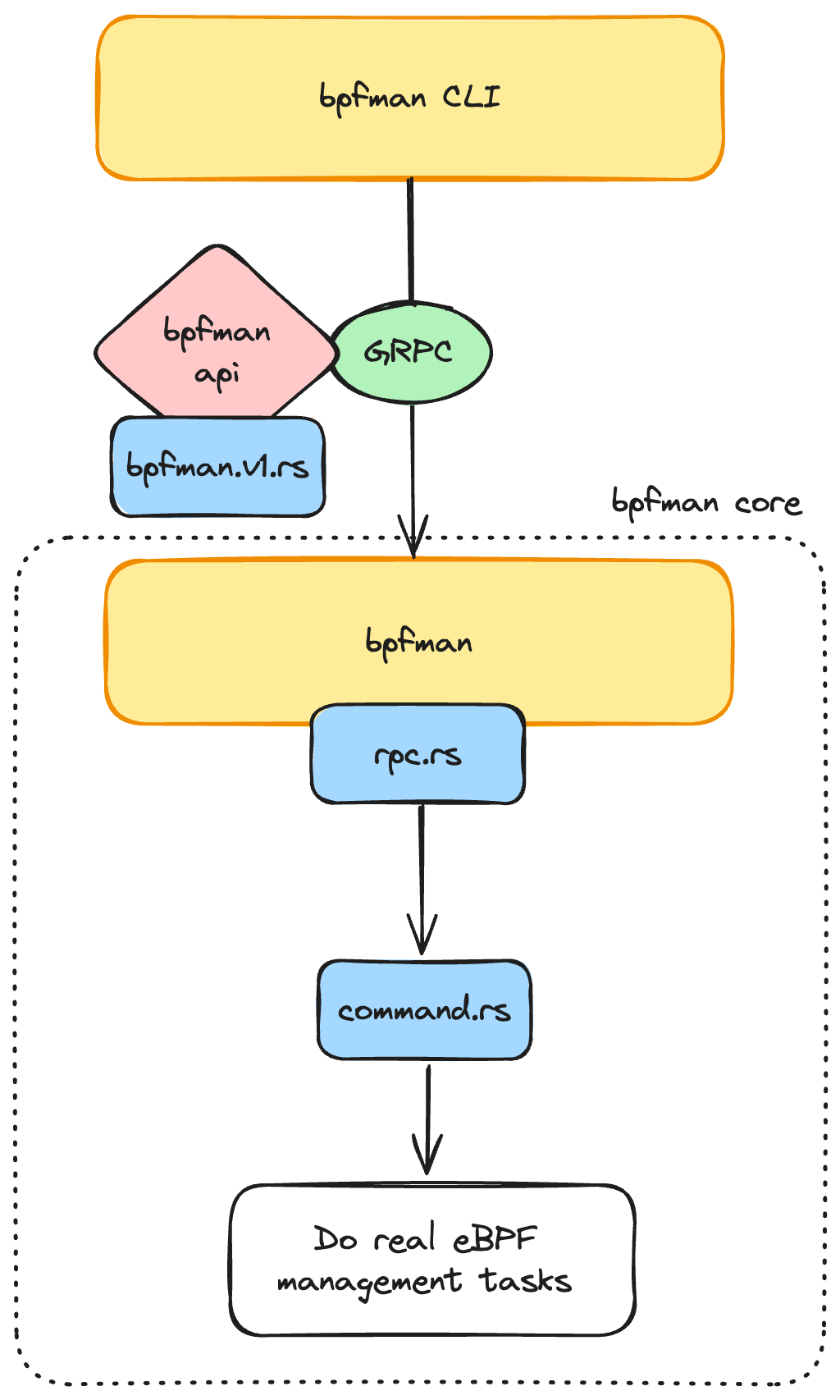
With this design there was a lot of data wrangling required to convert the
tonic generated rust bindings for the protocol buffer API into data
structures that were useful for bpfman. Specifically, data would arrive
via GRPC server as specified in bpfman.v1.rs where rust types are inferred
from the protobuf definition. In rpc.rs data was then converted to an
internal set of structures defined in command.rs. Prior to pull request #683
there was an explosion of types, with each bpfman command having it's own set of
internal structures and enums. Now, most of the data for a program that bpfman
needs internally for all commands to manage an eBPF program is stored in
the ProgramData structure, which we'll take a deeper look at a bit later.
Additionally, there is extra complexity for XDP and TC program types
which rely on an eBPF dispatcher program to provide multi-program support on
a single network interface, however this article will try to instead focus
on the simpler examples.
The tree of data stored by bpfman is quite complex and this is made even more
complicated since bpfman has to be persistent across restarts.
To support this, raw data was often flushed to disk in the form of JSON files
(all types in command.rs needed to implement serde's Serialize and
Deserialize). Specific significance would also be encoded to bpfman's
directory structure, i.e all program related information was encoded in
/run/bpfd/programs/<ID>. The extra infrastructure and failure modes introduced
by this process was a constant headache, pushing the community to find a better
solution.
Why Sled?
Sled is an open source project described in github as "the champagne of beta embedded databases". The "reasons" for choosing an embedded database from the project website are pretty much spot on:
Embedded databases are useful in several cases:
- you want to store data on disk, without facing the complexity of files
- you want to be simple, without operating an external database
- you want to be fast, without paying network costs
- using disk storage as a building block in your system
As discussed in the previous section, persistence across restarts, is one of bpfman's core design constraints, and with sled we almost get it for free! Additionally due to the pervasive nature of data management to bpfman's core workflow the data-store needed to be kept as simple and light weight as possible, ruling out heavier production-ready external database systems such as MySQL or Redis.
Now this mostly focused on why embedded dbs in general, but why did we choose sled...well because it's written in :crab: Rust :crab: of course! Apart from the obvious we took a small dive into the project before rewriting everything by transitioning the OCI bytecode image library to use the db rather than the filesystem. Overall the experience was extremely positive due to the following:
- No more dealing directly with the filesystem, the sled instance is flushed to the fs automatically every 500 ms by default and for good measure we manually flush it before shutting down.
- The API is extremely simple, traditional get and insert operations function as expected.
- Error handling with
sled:Erroris relatively simple and easy to map explicitly to abpfmanError - The db "tree" concept makes it easy to have separate key-spaces within the same instance.
Transitioning to Sled
Using the new embedded database started with the creation of a sled instance
which could be easily shared across all of the modules in bpfman. To do this we
utilized a globally available [lazy_static] variable called ROOT_DB in
main.rs:
#[cfg(not(test))]
lazy_static! {
pub static ref ROOT_DB: Db = Config::default()
.path(STDIR_DB)
.open()
.expect("Unable to open root database");
}
#[cfg(test)]
lazy_static! {
pub static ref ROOT_DB: Db = Config::default()
.temporary(true)
.open()
.expect("Unable to open temporary root database");
}
This block creates OR opens the filesystem backed database at /var/lib/bpfman/db
database only when the ROOT_DB variable is first accessed, and also allows for
the creation of a temporary db instance if running in unit tests. With this setup
all of the modules within bpfman can now easily access the database instance
by simply using it i.e use crate::ROOT_DB.
Next the existing bpfman structures needed to be flattened in order to work
with the db, the central ProgramData can be used to demonstrate how this was
completed. Prior to the recent sled conversion that structure looked like:
/// ProgramInfo stores information about bpf programs that are loaded and managed
/// by bpfd.
#[derive(Debug, Serialize, Deserialize, Clone, Default)]
pub(crate) struct ProgramData {
// known at load time, set by user
name: String,
location: Location,
metadata: HashMap<String, String>,
global_data: HashMap<String, Vec<u8>>,
map_owner_id: Option<u32>,
// populated after load
kernel_info: Option<KernelProgramInfo>,
map_pin_path: Option<PathBuf>,
maps_used_by: Option<Vec<u32>>,
// program_bytes is used to temporarily cache the raw program data during
// the loading process. It MUST be cleared following a load so that there
// is not a long lived copy of the program data living on the heap.
#[serde(skip_serializing, skip_deserializing)]
program_bytes: Vec<u8>,
}
This worked well enough, but as mentioned before the process of flushing the data to disk involved manual serialization to JSON, which needed to occur at a specific point in time (following program load) which made disaster recovery almost impossible and could sometimes result in lost or partially reconstructed state.
With sled the first idea was to completely flatten ALL of bpfman's data into a
single key-space, so that program.name now simply turns into a db.get("program_<ID>_name"),
however removing all of the core structures would have resulted in a complex diff
which would have been hard to review and merge. Therefore a more staged approach
was taken, the ProgramData structure was kept around, and now looks like:
/// ProgramInfo stores information about bpf programs that are loaded and managed
/// by bpfman.
#[derive(Debug, Clone)]
pub(crate) struct ProgramData {
// Prior to load this will be a temporary Tree with a random ID, following
// load it will be replaced with the main program database tree.
db_tree: sled::Tree,
// populated after load, randomly generated prior to load.
id: u32,
// program_bytes is used to temporarily cache the raw program data during
// the loading process. It MUST be cleared following a load so that there
// is not a long lived copy of the program data living on the heap.
program_bytes: Vec<u8>,
}
All of the fields are now removed in favor of a private reference to the unique
[sled::Tree] instance for this ProgramData which is named using the unique
kernel id for the program. Each sled::Tree represents a single logical
key-space / namespace / bucket which allows key generation to be kept simple, i.e
db.get("program_<ID>_name") now can be db_tree_prog_0000.get("program_name).
Additionally getters and setters are now built for each existing field so that
access to the db can be controlled and the serialization/deserialization process
can be hidden from the caller:
...
pub(crate) fn set_name(&mut self, name: &str) -> Result<(), BpfmanError> {
self.insert("name", name.as_bytes())
}
pub(crate) fn get_name(&self) -> Result<String, BpfmanError> {
self.get("name").map(|v| bytes_to_string(&v))
}
...
Therefore, ProgramData is now less of a container for program data and more of a
wrapper for accessing program data. The getters/setters act as a bridge
between standard Rust types and the raw bytes stored in the database,
i.e the [sled::IVec type].
Once this was completed for all the relevant fields on all the relevant types, see pull request #874, the data bpfman needed for it's managed eBPF programs was now automatically synced to disk :partying_face:
Tradeoffs
All design changes come with some tradeoffs: for bpfman's conversion to using
sled the main negative ended up being with the complexity introduced with the [sled::IVec type].
It is basically just a thread-safe reference-counting pointer to a raw byte slice,
and the only type raw database operations can be performed with. Previously when
using serde_json all serialization/deserialization was automatically handled,
however with sled the conversion is manual handled internally. Therefore, instead
of a library handling the conversion of a rust string (std::string::String) to
raw bytes &[u8] bpfman has to handle it internally, using [std::string::String::as_bytes]
and bpfman::utils::bytes_to_string:
pub(crate) fn bytes_to_string(bytes: &[u8]) -> String {
String::from_utf8(bytes.to_vec()).expect("failed to convert &[u8] to string")
}
For strings, conversion was simple enough, but when working with more complex rust
data types like HashMaps and Vectors this became a bit more of an issue.
For Vectors, we simply flatten the structure into a group of key/values with
indexes encoded into the key:
pub(crate) fn set_kernel_map_ids(&mut self, map_ids: Vec<u32>) -> Result<(), BpfmanError> {
let map_ids = map_ids.iter().map(|i| i.to_ne_bytes()).collect::<Vec<_>>();
map_ids.iter().enumerate().try_for_each(|(i, v)| {
sled_insert(&self.db_tree, format!("kernel_map_ids_{i}").as_str(), v)
})
}
The sled scan_prefix(<K>) api then allows for easy fetching and rebuilding of
the vector:
pub(crate) fn get_kernel_map_ids(&self) -> Result<Vec<u32>, BpfmanError> {
self.db_tree
.scan_prefix("kernel_map_ids_".as_bytes())
.map(|n| n.map(|(_, v)| bytes_to_u32(v.to_vec())))
.map(|n| {
n.map_err(|e| {
BpfmanError::DatabaseError("Failed to get map ids".to_string(), e.to_string())
})
})
.collect()
}
For HashMaps, we follow a similar paradigm, except the map key is encoded in
the database key:
pub(crate) fn set_metadata(
&mut self,
data: HashMap<String, String>,
) -> Result<(), BpfmanError> {
data.iter().try_for_each(|(k, v)| {
sled_insert(
&self.db_tree,
format!("metadata_{k}").as_str(),
v.as_bytes(),
)
})
}
pub(crate) fn get_metadata(&self) -> Result<HashMap<String, String>, BpfmanError> {
self.db_tree
.scan_prefix("metadata_")
.map(|n| {
n.map(|(k, v)| {
(
bytes_to_string(&k)
.strip_prefix("metadata_")
.unwrap()
.to_string(),
bytes_to_string(&v).to_string(),
)
})
})
.map(|n| {
n.map_err(|e| {
BpfmanError::DatabaseError("Failed to get metadata".to_string(), e.to_string())
})
})
.collect()
}
The same result could be achieved by creating individual database trees for
each Vector/HashMap instance, however our goal was to keep the layout
as flat as possible. Although this resulted in some extra complexity within the
data layer, the overall benefits still outweighed the extra code once the
conversion was complete.
Moving forward and Getting Involved
Once the conversion to sled is fully complete, see issue #860, the project will be able to completely transition to becoming a library without having to worry about data and state management.
If you are interested in in memory databases, eBPF, Rust, or any of the technologies
discussed today please don't hesitate to reach out at kubernetes slack on channel
#bpfman or join one of the community meetings to get involved.